Optimization of FPGA-based CNN Accelerators using Metaheuristics
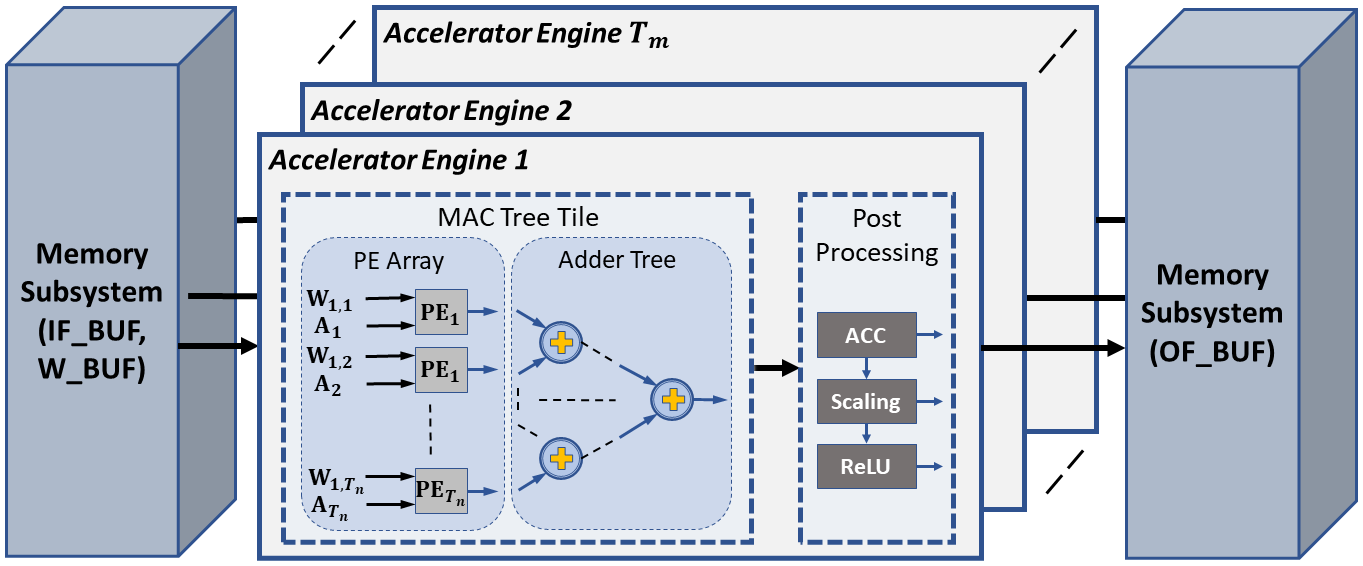
In recent years, convolutional neural networks (CNNs) have demonstrated their ability to solve problems in many fields and with accuracy that was not possible before. However, this comes with extensive computational requirements, which made general central processing units (CPUs) unable to deliver the desired real-time performance. At the same time, field-programmable gate arrays (FPGAs) have seen a surge in interest for accelerating CNN inference. This is due to their ability to create custom designs with different levels of parallelism. Furthermore, FPGAs provide better performance per watt compared to other computing technologies such as graphics processing units (GPUs). The current trend in FPGA-based CNN accelerators is to implement multiple convolutional layer processors (CLPs), each of which is tailored for a subset of layers. However, the growing complexity of CNN architectures makes optimizing the resources available on the target FPGA device to deliver the optimal performance more challenging. This is because of the exponential increase in the design variables that must be considered when implementing a Multi-CLPMulti-CLP accelerator as CNN’s complexity increases. In this paper, we present a CNN accelerator and an accompanying automated design methodology that employs metaheuristics for partitioning available FPGA resources to design a Multi-CLPMulti-CLP accelerator. Specifically, the proposed design tool adopts simulated annealing (SA) and tabu search (TS) algorithms to find the number of CLPs required and their respective configurations to achieve optimal performance on a given target FPGA device. Here, the focus is on the key specifications and hardware resources, including digital signal processors (DSPs), block random access memories (BRAMs), and off-chip memory bandwidth. Experimental results and comparisons using four well-known benchmark CNNs are presented demonstrating that the proposed acceleration framework is both encouraging and promising. The SA-/TS-based Multi-CLP achieves 1.31× − 2.37× higher throughput than the state-of-the-art Single-/Multi-CLP approaches in accelerating AlexNet, SqueezeNet 1.1, VGGNet, and GoogLeNet architectures on the Xilinx VC707 and VC709 FPGA boards.